📊 L'Intelligence Artificielle Révèle ses Sources : Analyse des Sites les Plus Cités
Découvrez quels sites alimentent les IA et comment cette sélection transforme l'écosystème numérique mondial.
Date : 2025-08-28
Tags : IA, LLM, RGPD, Innovation

L'intelligence artificielle générative transforme radicalement notre façon d'accéder à l'information. Derrière chaque réponse de ChatGPT, Claude ou Gemini se cache un écosystème complexe de sources de données qui façonnent les connaissances de ces modèles. Une récente analyse révèle quels sites internet alimentent prioritairement l'intelligence artificielle, soulevant des questions cruciales sur la diversité informationnelle, la propriété intellectuelle et l'avenir du web.
### Les Géants du Web Dominent l'Entraînement des IA
Les données révèlent une concentration massive des sources utilisées par les modèles de langage autour de quelques plateformes dominantes. Reddit émerge comme l'une des sources privilégiées, représentant une part substantielle des contenus utilisés pour l'entraînement. Cette préférence s'explique par la richesse conversationnelle de la plateforme, où millions d'utilisateurs échangent quotidiennement sur des sujets variés dans un format structuré et accessible.

Wikipedia constitue également un pilier fondamental de l'écosystème d'entraînement des IA. L'encyclopédie collaborative offre un corpus gigantesque d'informations factuelles, organisées et constamment mises à jour par une communauté mondiale. Sa structure standardisée et sa couverture encyclopédique en font une source incontournable pour développer les capacités de compréhension générale des modèles. Les sites d'actualités mainstream comme CNN, BBC ou Le Figaro complètent ce paysage en apportant une dimension temporelle et événementielle cruciale.
Les plateformes de questions-réponses comme Stack Overflow pour les développeurs ou Quora pour le grand public représentent une autre catégorie majeure. Ces espaces concentrent des milliers de problématiques concrètes accompagnées de leurs solutions, créant un terreau fertile pour développer les capacités de résolution de problèmes des IA. Cette diversité apparente masque néanmoins une réalité plus complexe quant à la représentativité réelle de ces sources.
### Impact Économique : Redistribution du Trafic Web
L'émergence des IA conversationnelles bouleverse l'économie numérique traditionnelle en modifiant fondamentalement les flux de trafic web. Les utilisateurs consultent désormais directement les IA plutôt que de naviguer vers les sites sources, créant un phénomène de "désintermédiation" massif. Cette transformation remet en question les modèles économiques basés sur la publicité display et les revenus générés par les visites directes.
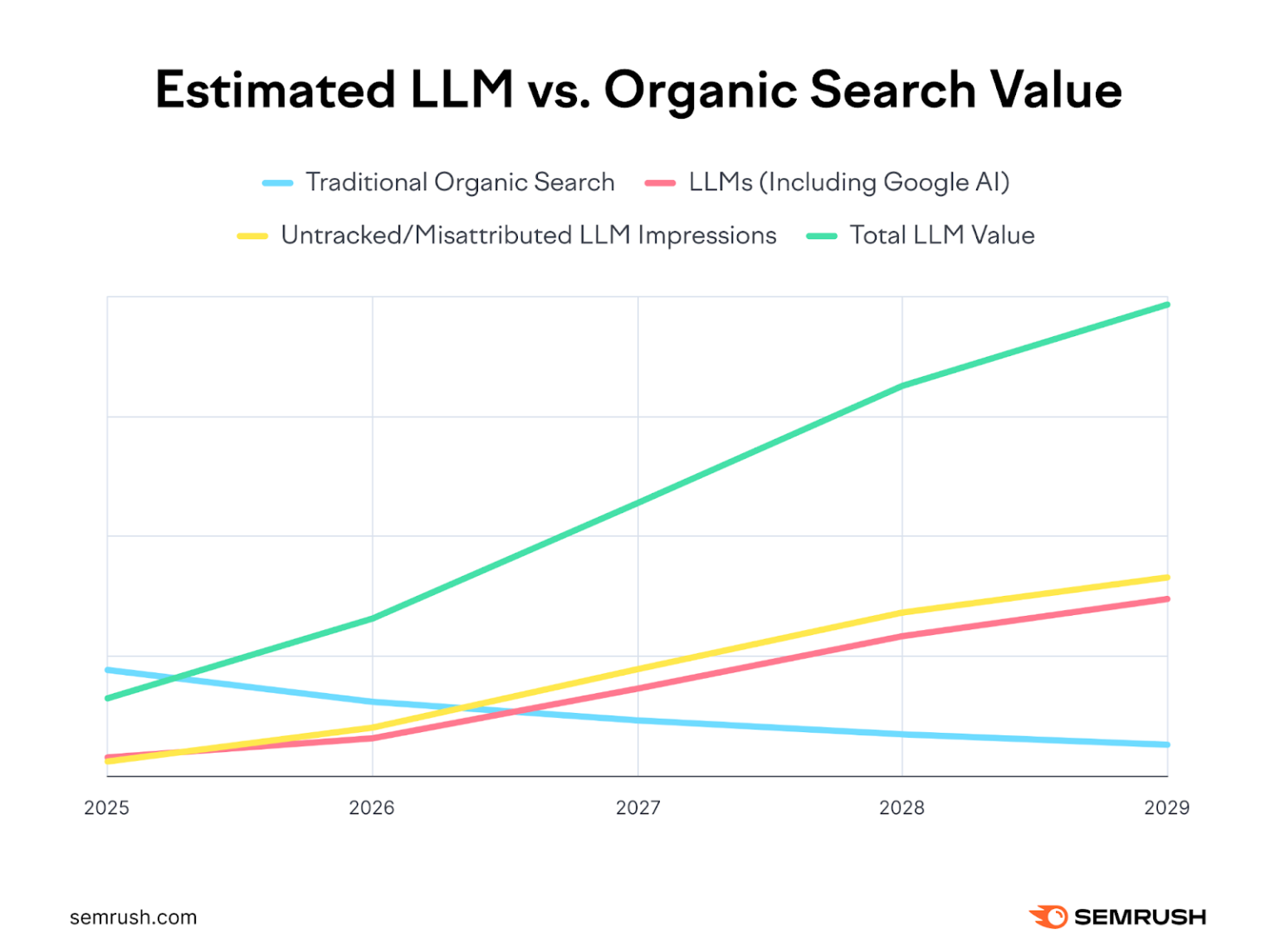
Les études récentes démontrent une corrélation négative entre l'adoption des IA et le trafic organique traditionnel. Les sites d'information, particulièrement vulnérables, voient leurs audiences diminuer tandis que leurs contenus continuent d'alimenter les modèles sans compensation directe. Cette asymétrie soulève des interrogations légitimes sur la durabilité du modèle actuel. Comment les créateurs de contenu peuvent-ils continuer à investir dans la production d'informations de qualité si leurs revenus s'amenuisent ?
Certaines plateformes tentent de négocier des accords directs avec les développeurs d'IA. Reddit a récemment signé des partenariats lucratifs avec Google et OpenAI pour licencier officiellement ses données. Ces accords créent un précédent important mais soulèvent également des questions d'équité : seules les grandes plateformes disposent du pouvoir de négociation nécessaire pour monétiser leurs contenus. Les créateurs individuels et les sites de taille modeste risquent de se retrouver exclus de cette nouvelle économie de la donnée.
### Biais et Représentativité : Les Angles Morts de l'IA
La concentration des sources d'entraînement autour de plateformes occidentales, anglophones et technophiles génère des biais structurels significatifs. Les modèles développent une vision du monde influencée par les communautés les plus actives sur ces plateformes, souvent jeunes, urbaines et techniquement compétentes. Cette surreprésentation crée des angles morts importants concernant les perspectives culturelles minoritaires, les langues moins répandues ou les communautés moins connectées.
L'analyse des sources révèle également une prédominance du contenu en anglais, même dans des modèles censés être multilingues. Cette hégémonie linguistique perpétue et amplifie les déséquilibres informationnels existants. Les nuances culturelles, les expressions idiomatiques ou les références historiques spécifiques à certaines régions risquent d'être mal comprises ou incorrectement retranscrites par des modèles entraînés principalement sur des corpus anglo-saxons.
La temporalité constitue un autre défi majeur. Les modèles figent leurs connaissances au moment de leur entraînement, créant un décalage croissant avec l'actualité. Bien que des mécanismes de mise à jour existent, ils ne compensent qu'partiellement cette limitation structurelle. Les événements récents, les évolutions scientifiques ou les changements sociétaux peuvent être absents ou incorrectement représentés dans les réponses générées.
La question de la vérification factuelle représente également un enjeu critique. Les plateformes communautaires comme Reddit, malgré leurs mécanismes de modération, contiennent inévitablement des informations erronées ou biaisées. Ces inexactitudes peuvent être amplifiées et propagées par les modèles d'IA, créant un effet de caisse de résonance pour la désinformation. L'absence de hiérarchisation qualitative dans l'utilisation des sources aggrave ce phénomène.
### Vers un Écosystème Plus Équilibré ?
Face à ces défis, plusieurs initiatives émergent pour diversifier et qualifier les sources d'entraînement des IA. Des projets collaboratifs visent à créer des corpus multilingues plus représentatifs, intégrant des perspectives culturelles variées. Les institutions académiques et les organisations internationales développent des bases de données spécialisées pour enrichir la connaissance des modèles dans des domaines spécifiques.
L'évolution réglementaire pourrait également transformer le paysage. Le Digital Services Act européen impose déjà certaines obligations de transparence aux plateformes d'IA concernant leurs sources de données. Ces réglementations pourraient s'étendre et créer un cadre plus équitable pour la rémunération des créateurs de contenu. L'établissement de standards industriels pour l'attribution et la compensation pourrait favoriser un écosystème plus durable.
Les innovations techniques offrent également des perspectives encourageantes. Les mécanismes d'attribution automatique permettent de tracer l'origine des informations utilisées par les modèles. Ces technologies pourraient faciliter la mise en place de systèmes de rémunération proportionnelle à l'utilisation des contenus. L'émergence de modèles fédérés, entraînés de manière distribuée sur des données locales, pourrait préserver la diversité culturelle tout en respectant la confidentialité.
L'intelligence artificielle redéfinit notre rapport à l'information et au savoir. Comprendre les mécanismes qui la sous-tendent devient essentiel pour naviguer efficacement dans cette nouvelle réalité numérique. Pour approfondir vos compétences et maîtriser ces outils révolutionnaires, découvrez notre [formation dédiée à l'optimisation de la productivité grâce à l'IA](https://www.travelearn.fr/formation/augmenter-productivite-creativite-ia), conçue pour vous accompagner dans cette transformation digitale.
Sources: [Profound](https://www.tryprofound.com/blog/ai-platform-citation-patterns), [Numerama](https://www.numerama.com/tech/1745374-les-publications-reddit-nechapperont-plus-a-chatgpt.html), [Visual Capitalist](https://www.visualcapitalist.com/ranked-the-most-cited-websites-by-ai-models/), [Semrush](https://www.semrush.com/blog/ai-search-seo-traffic-study/)