🐋 DeepSeek V4 : le LLM chinois qui défie GPT-5.5 à 1/6 du prix
DeepSeek V4-Pro code mieux que GPT-5.5, coûte 6x moins cher que Claude Opus 4.7. Contexte 1M tokens, open source, API promo jusqu'au 31 mai.
Date : 2026-05-04
Tags : DeepSeek, LLM, IA Générative, Open Source, Productivité

La Chine vient de frapper fort dans la course aux grands modèles de langage. Le 24 avril 2026, DeepSeek a mis en ligne DeepSeek V4 en accès preview : deux modèles open source, accessibles via API, capables de traiter jusqu'à un million de tokens en une seule fenêtre de contexte. Pour beaucoup d'observateurs, ce lancement est l'événement le plus marquant depuis DeepSeek R1, qui avait secoué le secteur en janvier 2025.
## Qu'est-ce que DeepSeek V4 et comment fonctionne ce nouveau modèle ?
DeepSeek V4 se décline en deux versions aux profils très différents. La première, DeepSeek-V4-Pro, est un modèle colossal de 1,6 trillion de paramètres, dont seulement 49 milliards sont activés à chaque inférence grâce à une architecture MoE (Mixture of Experts, c'est-à-dire un mélange d'experts spécialisés qui ne sont sollicités qu'en fonction du contexte de la requête). Cette approche permet d'obtenir des capacités de raisonnement proches des meilleurs modèles fermés tout en réduisant drastiquement les coûts de calcul. La seconde, DeepSeek-V4-Flash, est plus légère avec 284 milliards de paramètres totaux et 13 milliards activés, pensée pour la vitesse et les réponses immédiates. Les deux partagent une fenêtre de contexte d'un million de tokens, soit l'équivalent d'environ 750 000 mots, ce qui ouvre la voie à des analyses de documents entiers, de bases de code massives ou de conversations ultra-longues sans perte de cohérence. DeepSeek a introduit un mécanisme d'attention hybride inédit qui réduit à seulement 27% les coûts de calcul et à 10% la mémoire nécessaire par rapport à leur modèle précédent V3.2, à longueur de contexte équivalente. Les deux modèles sont disponibles en open source sur Hugging Face, entraînés sur 33 et 32 trillions de tokens respectivement, et accessibles via l'API ou en mode web (Expert pour V4-Pro, Instant pour V4-Flash).

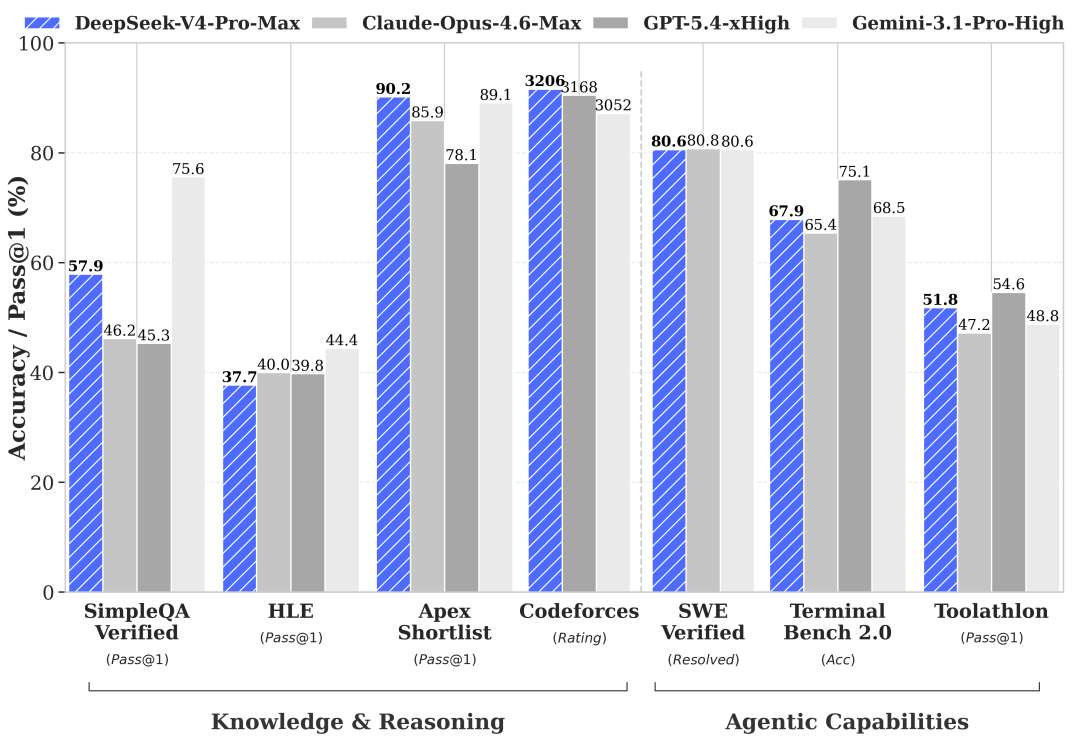
## DeepSeek V4 rivalise-t-il vraiment avec GPT-5.5 et Claude Opus 4.7 sur les benchmarks ?
La question que tout le monde se pose est simple : est-ce que ces chiffres impressionnants se traduisent par des performances réelles ? La réponse est nuancée, mais globalement très encourageante pour DeepSeek. Sur LiveCodeBench, le benchmark de référence pour le code, V4-Pro atteint 90,2%, devant GPT-5.5 (89,1%) et Claude Opus 4.7 (85,9%). Sur Codeforces, DeepSeek V4-Pro affiche un ELO de 3 206, surpassant GPT-5.5 à 3 168 et Gemini 3.1-Pro à 3 052. Sur SWE-bench Verified, qui mesure la capacité à résoudre de vrais problèmes de développement logiciel tirés de dépôts GitHub réels, DeepSeek V4-Pro affiche 80,6%, à seulement 0,2 point de Claude Opus 4.7 (80,8%). Là où DeepSeek marque encore le pas, c'est sur les benchmarks de connaissances factuelles : SimpleQA-Verified atteint 57,9% contre 75,6% pour Gemini-3.1-Pro, et sur HLE (Humanity's Last Exam), le test le plus exigeant qui soit, DeepSeek score 37,7% contre 44,4% pour Gemini. L'évaluation indépendante du NIST (CAISI) conclut que DeepSeek V4 se situe au niveau de frontier models d'il y a environ 8 mois, ce qui le place dans une position solide sans être le leader absolu sur tous les fronts.
| Benchmark | DeepSeek V4-Pro | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1-Pro |
|---|---|---|---|---|
| LiveCodeBench | 90,2% | 89,1% | 85,9% | 78,1% |
| Codeforces ELO | 3 206 | 3 168 | n/a | 3 052 |
| SWE-bench Verified | 80,6% | 80,6% | 80,8% | 67,9% |
| GPQA Diamond | 90,1% | 93,6% | 94,2% | n/a |
| HLE (Pass@1) | 37,7% | 39,8% | 40,0% | 44,4% |
| SimpleQA Verified | 57,9% | n/a | n/a | 75,6% |
## Pourquoi DeepSeek V4 coûte-t-il 6 fois moins cher que ses concurrents américains ?
C'est probablement le chiffre qui a fait le plus de bruit dans la communauté tech depuis le lancement. DeepSeek V4-Pro est proposé à 1,74 dollar par million de tokens en entrée (sans cache) et 3,48 dollars par million de tokens en sortie, contre 5 dollars à l'entrée et 30 dollars en sortie pour GPT-5.5, et 5 dollars et 25 dollars pour Claude Opus 4.7. La version Flash pousse encore la logique d'économie : 0,14 dollar à l'entrée et 0,28 dollar en sortie, soit 35 fois moins cher que GPT-5.5 sur les tokens de sortie. Avec le cache actif, l'écart s'agrandit encore : DeepSeek V4-Pro tombe à 0,145 dollar par million de tokens en entrée, soit environ un dixième du prix de GPT-5.5. Pour une entreprise qui utilise un LLM pour automatiser des tâches répétitives, analyser des documents clients ou alimenter un agent IA en production, cette différence de coût peut représenter une économie de dizaines de milliers d'euros par an, selon les volumes traités. Une promotion tarifaire est active jusqu'au 31 mai 2026 à 15h59 UTC, offrant des conditions encore plus avantageuses pour les premiers adoptants.
> "Welcome to the era of cost-effective 1M context length."
> — Équipe DeepSeek, annonce officielle du 24 avril 2026
## Comment les professionnels peuvent-ils exploiter DeepSeek V4 dans leurs workflows ?
Pour les indépendants, les PME et les équipes tech qui construisent des solutions IA, DeepSeek V4 ouvre des perspectives très concrètes. La fenêtre de contexte d'un million de tokens permet d'ingérer une base de code entière, un cahier des charges de 500 pages ou plusieurs mois d'historique de conversations clients en une seule requête, ce qui change profondément la donne pour les agents IA chargés d'analyser ou de synthétiser de grands volumes de données. Le modèle est compatible avec les standards d'API OpenAI, ce qui facilite son intégration dans des outils comme n8n, Make ou LangChain sans réécrire toute la stack technologique. Sur les tâches de code et d'automatisation, ses scores proches de Claude Opus 4.7 en font une alternative crédible à un coût sans commune mesure, en particulier pour les projets où le volume de tokens traités est élevé. Les professionnels qui souhaitent maîtriser la conception d'agents IA capables d'exploiter ce type de modèle à grande échelle trouveront dans la formation [Automatiser ses workflows et créer des agents IA](https://www.travelearn.fr/formation/automatiser-ses-workflows-et-crer-des-agents-ia) une méthode concrète pour passer du prototype à des systèmes fiables en production. À noter que DeepSeek reste sous vigilance réglementaire dans plusieurs pays : plusieurs gouvernements ont restreint son usage sur les réseaux officiels en raison de la localisation des données en Chine, un point à intégrer pour tout projet sensible ou soumis au RGPD.
---
**Sources**
- [DeepSeek V4 Preview Release — API Docs officiels](https://api-docs.deepseek.com/news/news260424)
- [Tout ce qu'il faut savoir sur DeepSeek V4 — Euronews](https://www.euronews.com/next/2026/04/24/chinas-deepseek-releases-new-ai-model-v4-heres-everything-to-know-as-the-ai-race-speeds-up)
- [DeepSeek V4-Flash est 35x moins cher que GPT-5.5 — RevolutionInAI](https://www.revolutioninai.com/2026/05/deepseek-v4-flash-vs-gpt-5-5-cost-comparison-2026.html)
- [CAISI Evaluation of DeepSeek V4 Pro — NIST](https://www.nist.gov/news-events/news/2026/05/caisi-evaluation-deepseek-v4-pro)
- [DeepSeek V4 Complete Guide — CoderSera](https://codersera.com/blog/deepseek-v4-complete-guide-2026/)